인공지능 데이터 편향성을 개선하는 방법? 실제 사례를 통한 해결 방안 소개
인공지능 데이터 편향성이란 무엇이고, 발생하는 원인은 무엇일까요? 실제 사례부터 국내 기업의 해결 방안까지, 모두 알아보겠습니다.

최근 우리 삶을 편리하게 만드는 생성형 AI 도구가 계속해서 늘어나고 있습니다. 영상 제작, 광고 배너 제작, 인물 사진 제작 도구 등 다양하죠. 여기에 자동화 시스템, 채용 솔루션, 마케팅 분석 툴에서도 AI가 활용되고 있습니다.
그 덕분에 업무 시간은 줄이고, 생산성은 높일 수 있죠. 그런데 이처럼 AI로 인해 기업이 살아나기도 하지만, 반대로 AI로 인해 기업이 무너질 수도 있다는 사실, 알고 계시나요? 그 원인은 ‘AI 편향성’입니다.
인공지능 데이터 편향성이란?
여러분, ‘근묵자흑(近墨者黑)’이라는 사자성어를 아시나요? ‘검은 먹과 가까이하면 검게 물든다’, 좋지 못한 사람과 가까이하면 좋지 못한 사람으로 물들게 되니, 이를 경계해야 한다는 뜻이 담겨 있습니다.
그런데 흥미롭게도 인공지능에도 근묵자흑이 나타납니다. AI는 온전히 스스로 생각하는 존재가 아니에요. 인간이 제공한 데이터로 학습합니다. 이때 제공하는 데이터 중 ‘먹’처럼 좋지 못한 데이터가 있다면? 편견, 오류로 가득한 데이터를 학습한 AI는 검게 물들어 버립니다.

인공지능 데이터 편향성이 발생하는 원인은 무엇일까?
데이터 종합병원, '데이터클리닉'은 그 원인을 3가지로 정리했습니다.
- 데이터셋 자체: 데이터 자체가 편향되어 있을 때를 말합니다. 특정 데이터셋이 양적으로 지나치게 과밀하거나 과소한 것이죠. 데이터셋 자체가 편향되어 있으니 편향된 학습이 이루어지고, 편향된 판단을 내립니다.
- 데이터 라벨링: 학습 데이터에 라벨을 지정하는 과정에서도 편향이 발생할 수 있어요. 원본 데이터를 식별하는 데에서 오류가 발생하거나, 정확한 맥락을 주지 않아서 일관되지 않은 라벨을 사용하는 것이죠.
- 개발자의 편향된 시각: 개발자가 데이터셋을 준비하는 과정에서 개발자 스스로가 무의식적으로 가진 편향된 관점이 녹아들고, 특정 데이터셋에 가중치를 두어 프로그래밍을 하게 돼요.
대표적인 인공지능 데이터 편향성 사례 2가지
이러한 문제들을 해결하지 못한다면 어떤 상황이 발생할까요? 대표적인 2가지 사례를 확인해 볼게요.
아마존 AI 채용 도구
2018년 아마존은 채용 프로세스를 효율화하기 위해 인공지능을 도입했어요. 채용 담당자들의 당장의 업무량 자체는 줄일 수 있었지만, 결과적으로 기업에 악영향을 주었습니다.
아마존의 인공지능이 실제 채용 과정에서 ‘여성’이라는 단어가 포함된 이력서에 불이익을 준 것이죠. 왜 이런 결과가 나왔을까요?

시간이 지난 현재는 미국 500대 기업 중 99%가 AI 채용을 도입한 상황입니다. 하지만 아마존의 사례처럼 채용 과정에서 차별이 발생할 가능성, 여전히 존재합니다.
이러한 흐름에 따라 미국은 AI 편향성에 대한 규제 ‘NYC 144’를 발표하며 규제를 강화했습니다. 채용 과정에 있어서 인공지능 데이터 편향성에 대한 결과 보고서를 발표하지 않으면, 지연일수마다 최대 1500달러(한화로 200만 원)의 벌금을 납부해야 해요.
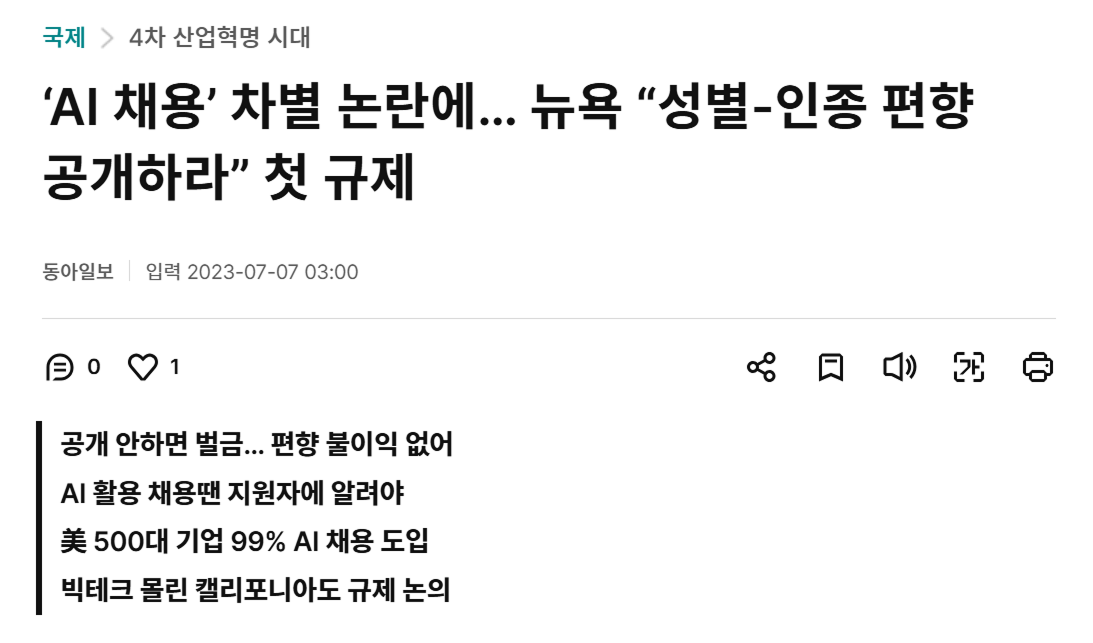
해외 사례이지만, 이는 곧 한국의 미래가 될 수 있습니다. 심지어 한국은 해외보다 AI 데이터에 대한 규제가 더욱 엄격하죠.
1) 기업에 대한 부정적인 이미지 형성
2) 업무에 비효율이 발생하는 건 물론,
3) 법적 규제로 인해 ‘벌금 폭탄’까지 받게 됩니다.
따라서 법적 규제의 가이드라인까지 꼼꼼히 체크해야 해요!
안면 인식 기술
AI 기술이 대표적으로 활용되는 안면 인식 기술이죠. 그런데 젠더쉐이즈(Gender Shades) 프로젝트, 미국 표준 기술연구소(NIST)가 주요 커머스 기업들이 안면 인식 기술을 분석한 결과, 데이터셋이 주로 백인의 얼굴에 초점이 맞추어져 있다는 사실을 발견했어요.
즉 그 외의 라틴계, 중동인, 동양인, 흑인 등 다양한 인종의 데이터가 부족하여 부정확한 식별이 이루어지는 것이죠. 한 가지 예로, 남아프리카 공화국의 평균 얼굴 이미지는 타 아프리카 국가에 비해 좀 더 밝은색으로 계산되는 오류가 나타나요.

SM 버추얼 아이돌 제작사 자이언트스텝, 버추얼 휴먼 제작 시 어떻게 AI 편향성을 극복했을까?
또한 국내에서도 인공지능 데이터 편향성을 겪은 실제 사례가 있습니다. ‘자이언트스텝’은 XR, VFX부터 버추얼 휴먼 디자인까지 전문적으로 진행하는 비주얼 콘텐츠 솔루션 기업이에요.
유튜브 알고리즘에서 아래 버추얼 휴먼을 보신 분들 계실 거예요! 자이언트스텝은 버추얼 휴먼 제작 전문가이기도 합니다. SM엔터테인먼트 버추얼 아이돌 ‘나이비스’, 네이버의 최초 버추얼 휴먼 인플루언서 ‘이솔’을 제작했어요.

자이언트스텝의 FacialX, AI 편향성으로 인해 난관을 겪었습니다.
이처럼 탄탄한 포트폴리오를 쌓아온 자이언트스텝, 알고 보면 내부 AI 팀에서 큰 난관을 겪고 있었다고 하죠. 자이언트스텝은 표정, 모션을 자연스럽게 구사하는 ‘버추얼 액터’를 제작할 수 있는 장치 ‘FacialX’를 개발하고 있었습니다.
하지만 자이언트스텝도 인공지능 데이터 편향성을 피해 갈 수 없었습니다. 특정 얼굴 유형에 쏠린 데이터만을 보유한 터라 FacialX의 인식 정확도는 떨어졌죠.
데이터클리닉을 만난 후, 어떻게 변했을까요?
결국 자이언트스텝 AI 팀은 ‘데이터 종합병원’이라 불리는 데이터클리닉을 찾아왔습니다. 데이터클리닉을 만난 후, 건강한 데이터를 학습하며 FacialX의 성능은 비약적으로 상승했습니다. 그 변화 과정을 살펴볼게요!
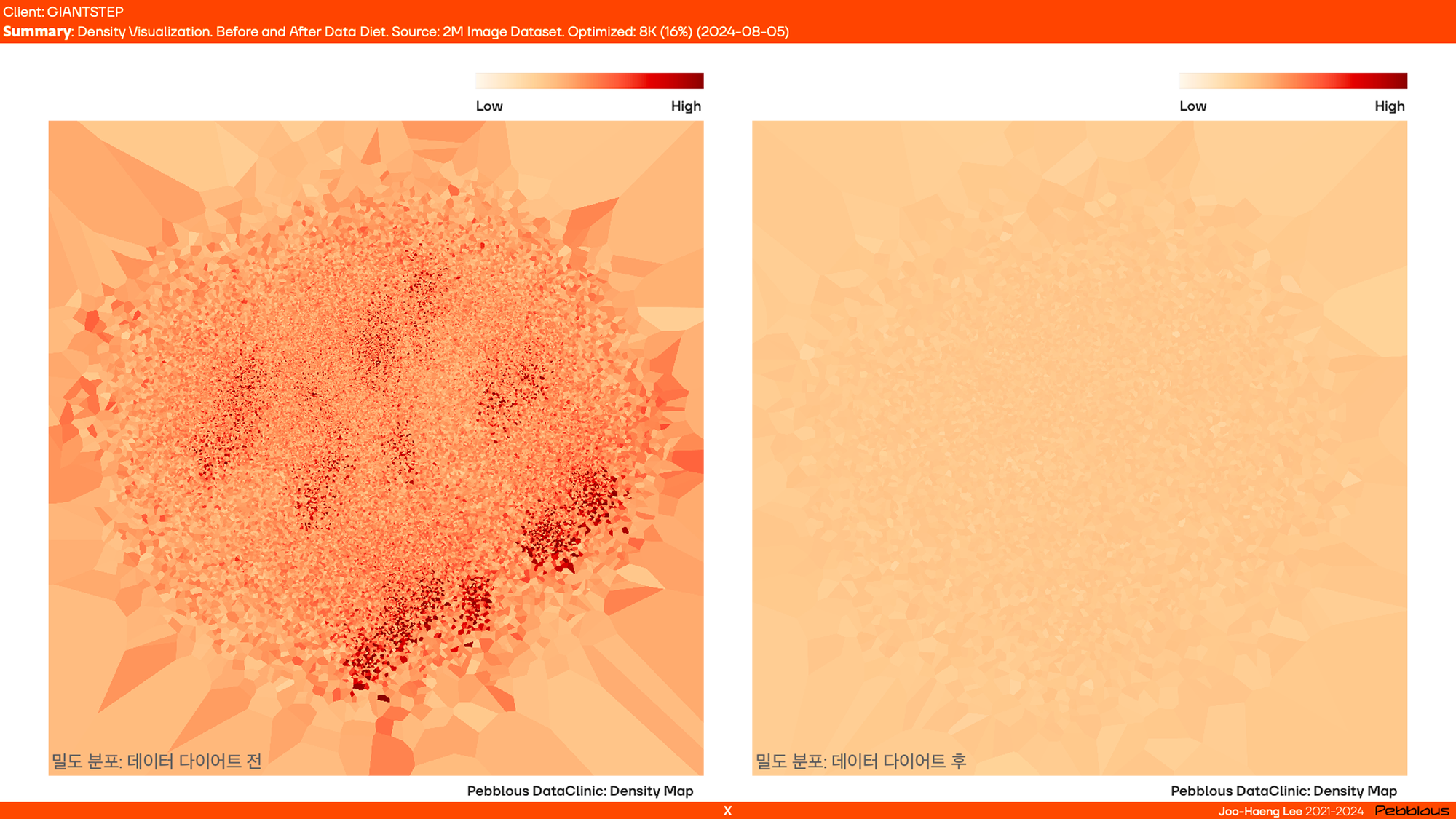
데이터 다이어트: 중복 데이터를 제거해 데이터 200만 건 → 약 40만 건으로 축소
자이언트스텝에서 방대한 양의 합성 데이터를 생성했다고 했었죠? 하지만 중복 데이터가 다수였기에 첫 번째로 데이터 다이어트가 필요했어요.
- 데이터 렌즈(Diagnostic Lens)로 원본 데이터셋의 표정 분포, 인종별 비율, 조명, 각도를 정밀하게 분석했어요.
- 이 중 근육처럼 반드시 필요한 데이터, 내장지방처럼 불필요한 중복 데이터를 철저히 구분하여 중복 데이터를 제거했어요. 200만 건의 데이터 중 5분의 1로 줄여, 40만 건의 데이터를 남겼습니다.
- 데이터셋을 극도로 효율화한 환경을 만든 덕분에 이전보다 인공지능의 학습 시간은 더욱 빨라졌어요!
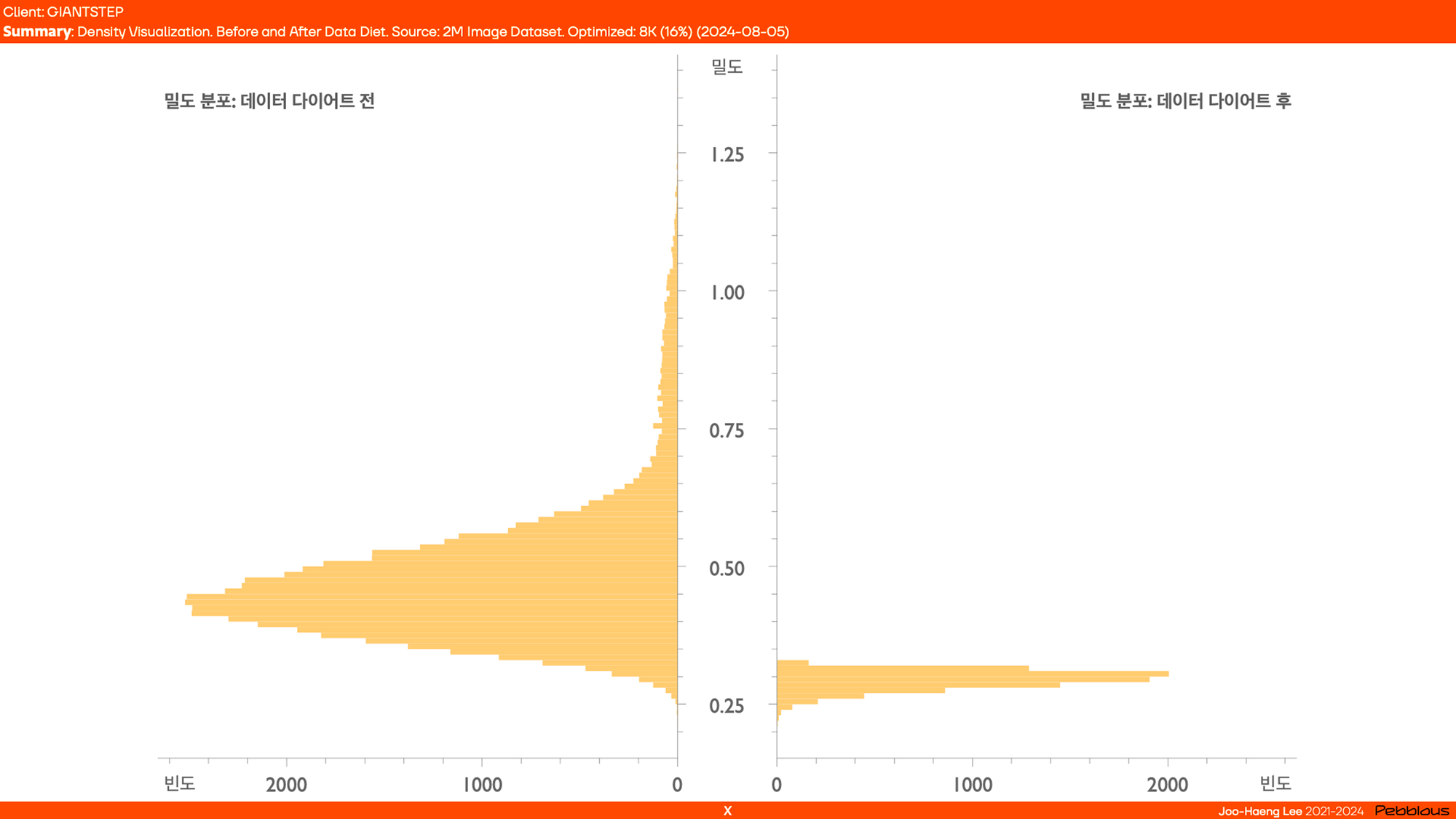
아래는 벡터 임베딩을 시각화하여 데이터 다이어트 전후를 비교한 모습이에요. 그 전에는 과밀한 부분이 다수 존재했는데,데이터 다이어트 이후 일정한 밀도로 변환되었습니다.
*벡터 임베딩이란? 텍스트, 이미지, 오디오와 같은 ‘비정형 데이터’를 기계가 인식할 수 있도록, 숫자 배열(벡터)로 바꾸는 방법이에요.
또다른 형태, 밀도 히스토그램으로 확인해 볼까요? 막대가 길수록 밀도가 높아지는데요. 데이터가 과밀한 구간, 그렇지 않은 구간이 확연히 보이죠. 데이터 다이어트 후, 과밀한 통계적 이상치(Outlier) 부분이 사라졌어요.
*통계적 이상치: 데이터 분포에서 벗어난 극단적인 값이에요. 전체의 패턴을 벗어나 지나치게 높거나 작은 값을 말합니다.
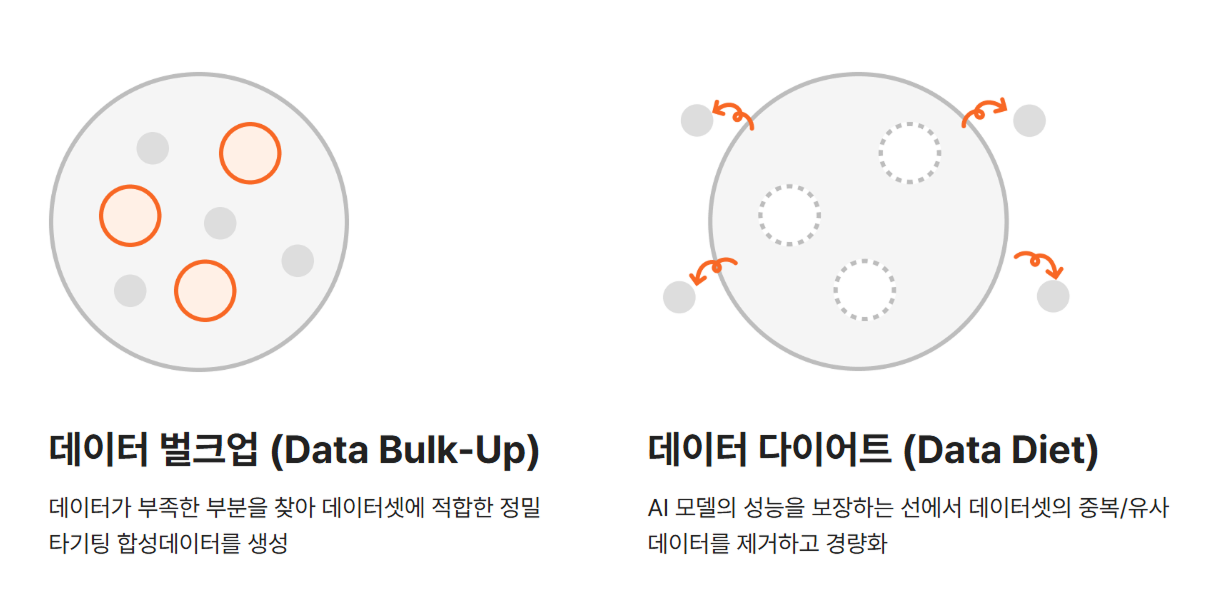
데이터 벌크업(합성 데이터 생성): 단 66명의 데이터로 성능 상승.
데이터 다이어트로 근육처럼 건강한 데이터를 남겨두었다면, 인공지능 데이터 편향성에서 벗어나 좀더 세밀한 표정 변화를 구현하기 위해서는 이른바 데이터 벌크업, ‘합성 데이터’ 생성은 필수입니다.
사실 기존에 자이언트스텝도 자체적으로 방대한 합성 데이터를 생성했지만, 모델의 성능을 향상시키기에는 효율이 부족했어요. 더 나은 해결책이 필요한 상황에서, 데이터클리닉은 이렇게 해결했어요!
- 데이터 렌즈로 이미지를 다각도로 분석하자, 실제 데이터의 60% 이상이 특정 조건에 집중되어 있었다는 점을 발견했죠. 이른바 편향을 수치화하는 과정이 필요했어요.
- 반드시 꼭 필요한 부분에만, 편향 없는 합성 데이터를 만드는 방법 없을까요? 데이터클리닉에 있습니다. 페블러스에서는 이를 '정밀 타기팅 합성 데이터'라고 부르는데요.
- 정밀 타기팅 합성 데이터는 마치 ‘보톡스’와 같아요. 정말 필요한 주름에만 소량의 보톡스를 넣어도, 팽팽한 얼굴을 만들어지죠. 보톡스처럼 여러분께 정말 필요한 데이터에 대한 합성 데이터만을 생성하고 있어요.
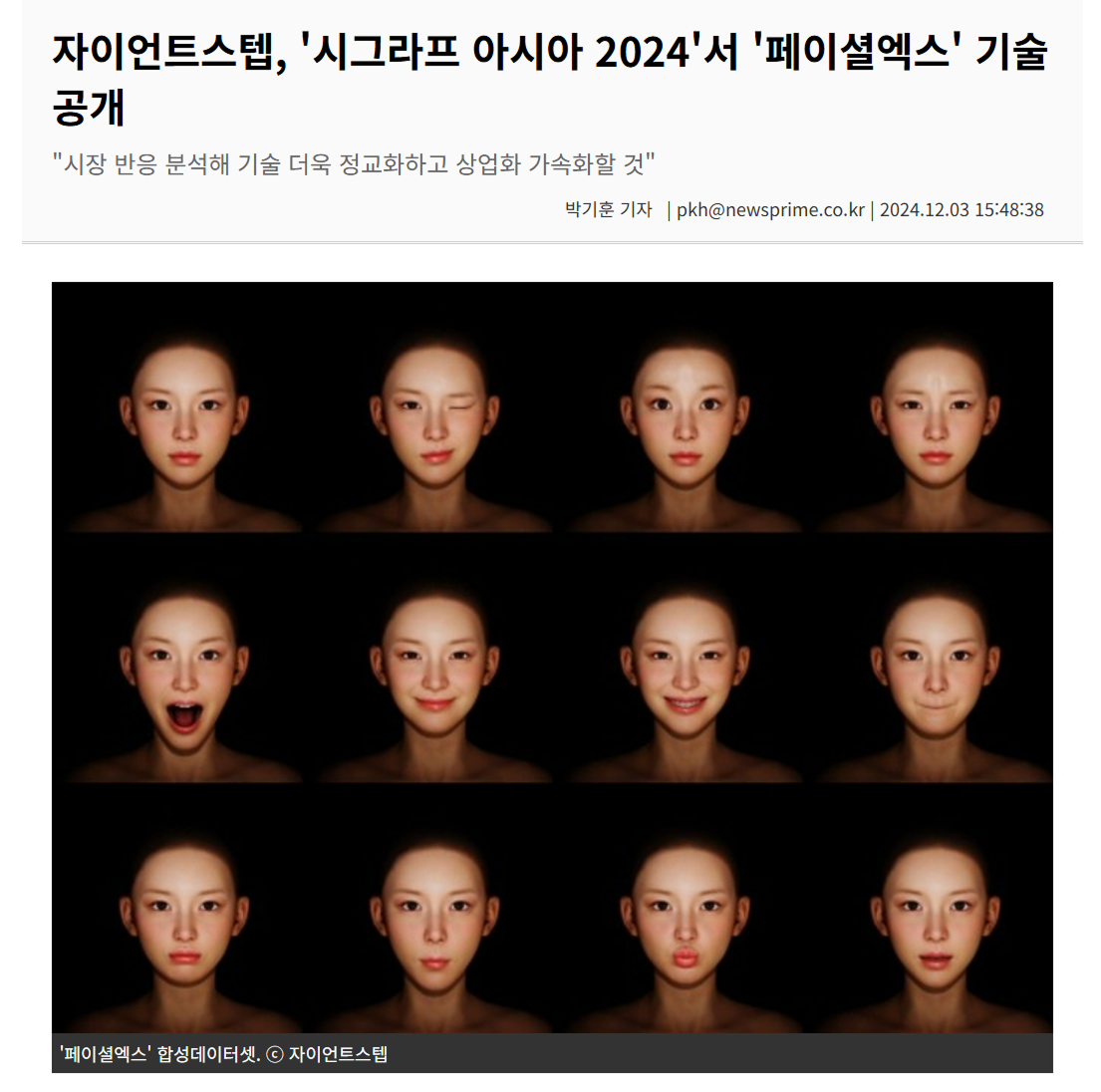
이후 FacialX의 성능, 어떻게 바뀌었을까요? 최종적으로 아래와 같은 결과물을 만들어낼 수 있었어요. 지금까지 여러분이 봐오셨던 어색한 버추얼 휴먼이 아닌 마치 실제 인간처럼 생동감 있는 표정을 만들어내고 있습니다.

덕분에 자이언트스텝의 FacialX는 무사히 런칭되어 세계 최대 규모의 컴퓨터 그래픽 및 인터랙티브 기술 컨퍼런스 ‘시그라프 아시아 2024’에서 공개되었습니다.
또한 연구 결과는 관련 분야 우수 학술대회인 SIGGRAPH Asia 2024에서 논문으로 소개되기도 했어요. 영광스럽게도 페블러스도 공동 저자로 연구 논문에 참여하게 되었습니다.

어쩌면 우리 기업의 AI도 편향 문제가 심각한 것은 아닐까?
지금까지 채용, 얼굴 인식 기술, 버추얼 휴먼에 대해서만 말씀드렸지만, 사실 데이터의 품질에서 시작된 AI 편향성은 그 어떤 분야든 발생할 수 있습니다. 예를 들어볼까요?
- 의료: 만일 의료 진단을 돕는 AI를 개발한다면 어떨까요? 특정 질병, 성별에 대한 데이터를 충분히 학습하지 않아 진단 정확도가 떨어질 수 있어요. 오진으로 인해 환자는 잘못된 치료를 진행하고, 건강 상 피해를 입습니다.
- 치안: 국가 치안을 막기 위해 인공지능을 개발할 때 편향성이 나타난다면? 소수 지역의 범죄율을 과대 예측할 수 있습니다. 과잉 치안으로 인해 인력이 손실되고, 그로 인해 그 외 지역의 범죄율이 높아질 수 있습니다.
- 신용 평가: AI가 과거 금융 데이터를 바탕으로 ‘대출을 받지 못한 사람들’의 특성을 부정적으로 인식합니다. 단지 소득이 일정하지 않거나, 특정 지역에 거주한다는 이유만으로 ‘리스크가 높다’고 판단하여 기존에는 대출이 가능했던 고객까지 부당하게 거절하게 돼요.
하지만 걱정하지 마세요. AI 편향성 문제는 해결이 가능합니다. 지금의 자이언트스텝처럼, 페블러스와 함께 편향성을 극복하고 건강한 AI로 만들어 나가는 기업들이 많습니다. 데이터클리닉의 진단 리포트 샘플을 통해 또 다른 사례를 알아보세요!
AI Hub 산업폐기물 이미지 데이터셋 진단 보고서 (1M)
AI Hub K-Fashion 데이터셋 진단 보고서 (1M)
편향성을 감소시키는 해결 방안, 이렇게 해보세요.
1) 주관적인 시각 대신, 데이터 렌즈로 ‘객관적’으로 분석하세요.
데이터 작업자, 데이터 엔지니어, AI 연구자와 같은 내부 인력이 모든 데이터를 직접 진단하면 시간은 많이 드는 건 물론, 무의식 속 편향성 때문에 또다시 잘못된 판단을 할 수 있어요.
2) 과도한 데이터는 줄이고, 과소한 데이터는 늘려보세요.
무조건 양이 많다고 좋은 데이터가 아닙니다. GPU 낭비로 인해 효율이 떨어지고요. 또한 개별적으로는 우수한 데이터라도, 그 양이 적다면 편향성은 더욱 짙어져요.
3) 벌금 폭탄을 막기 위한 예방책, ‘AI 규제 거버넌스’
당장은 데이터 품질을 바로 잡았지만, 또다시 편향이 발생하면 기업 입장에서 브랜드 이미지 타격, 벌금 등 치명적인 손실이 발생할 수도 있어요.
그래서 AI가 또다시 같은 편향을 반복하지 않고, 안전한 상황을 유지하기 위해서 현 규제에 대해 꼼꼼히 숙지하고 계시는 것이 중요합니다.
- 데이터클리닉 2.0은 인공지능이 자체적으로 규제를 학습하고, 스스로 AI의 편향성을 관리해요.
- AADS는 국제 표준인 ISO/IEC 25012와 5259의 데이터 품질 평가 기준을 이해하고, 이 기준에 따라 데이터의 품질 평가를 수행해요.
- AADS로 NYC 144, EU AI Act와 같은 규제를 안전하게 준수하고, 막대한 벌금을 예방할 수 있어요. 예를 들면 NYC 144의 경우 매달 월 200만 원의 벌금을, EU AI Act은 무려 글로벌 매출액의 7% 또는 3,500만 유로(약 527억 원)의 벌금을 막을 수 있습니다.

지금 당장은 건강한 데이터셋일지라도, 그 건강이 영원하리라 보장할 수는 없습니다. 고객의 취향과 세상의 규제는 꾸준히 변화하니까요. 데이터 건강 관리, 꾸준히 해야 합니다.
데이터 건강을 놓친 후 뒤늦게 후회하시기 보다는, 데이터클리닉 2.0을 통해 미리 여러분의 데이터 건강을 지키시길 바라겠습니다.
데이터클리닉 홈페이지에서 '문의하기' 버튼을 누르신 후, 인공지능 데이터 편향성에 대한 모든 고민을 편히 말씀해 주세요. 데이터 품질 관리 전문가가 직접 심도 있게 고민 후 답변을 드리겠습니다.
우리 데이터, 과연 이대로 괜찮을까? 미래가 걱정된다면
AI 모델 성능 80% 높이는 데이터 관리 노하우?