데이터 품질 진단 시점, 이때가 최고의 타이밍입니다.
데이터 품질 진단 시점, 언제가 최적의 시점일까요? 품질 진단 시점을 놓치지 않고 꾸준히 관리하는 방법, 모두 알려드리겠습니다.

데이터 품질 진단 시점, ‘최고’의 타이밍? 사실 그런 건 없습니다.
데이터클리닉은 데이터를 ‘살아 움직이는 생명체’ 같은 존재라고 생각합니다.
데이터는 수집되고, 저장되고, 분석되고, 모델로 활용되며 계속해서 움직이죠. 그 과정에서 데이터에 오류가 생기거나 변화할 수도 있고요. 오늘은 깨끗했던 데이터가 내일은 갑자기 오류를 포함할 수도 있습니다.
데이터 품질 진단, 왜 필요한 걸까?
여러분이 속한 조직은 꾸준히 데이터 품질진단을 해내고 있나요? 만약 조금이라도 소홀히 한다면, 이런 상황이 발생합니다.
- 데이터 품질진단을 소홀히 하면, 여러분의 눈에 당장 보이지 않는 비용들이 새어나갑니다. 바로 ‘시간’에 대한 비용이죠. 몇몇 값에 오류가 생기면 도미노처럼 AI 서비스가 무너집니다.
- 팀 전체가 위기에 봉착합니다. ETL 로그를 다시 보고, 누군가는 원본 DB를 뒤져야 합니다. 누군가는 고객의 불만 폭주를 막기 위해 임시 공지를 쓰고요.
- 또한 공공데이터처럼 데이터를 외부에 공개하는 경우도 있는데요. 이때 연구자나 기업 담당자들은 공개된 데이터를 그대로 활용하게 됩니다. 이때 품질이 낮은 데이터 하나로 인해 수백 명의 사용자에게 불편함을 줄 수 있어요.
이처럼 데이터 품질 관리에 소홀히 한다면, 기업의 모든 이해관계자들이 난감한 상황에 처하게 됩니다. 즉 데이터가 병든다면, 연구원, 엔지니어, 서비스 기획자, CEO, 고객 등 모두가 힘들어집니다.
데이터 품질 진단 절차
데이터가 살아 있는 모든 단계에 걸쳐서 데이터 품질을 진단하고 개선해야 하는데요. 프로세스별로 어떻게 품질진단을 해야 하는지 말씀드리겠습니다.
1. 품질 진단 계획 수립
목표를 정의해야 단순 점검이 아니라, ‘문제 해결’에 초점을 맞추게 됩니다. 아래 2가지 질문에 답변해보며 목표를 정의해보세요.
- 전체 중 어떤 데이터를 대상으로 진단할까?
- 어떤 품질 문제를 해결할까?
- 적절한 목표 정의 예시: 현재 AI 모델의 학습데이터가 최신 시장 동향을 반영하고 있는지, ISO 5259 표준 기준의 데이터 적시성(Timeliness)을 반영하고 있는지 확인하고 개선하고 싶다.
2. 품질 진단
계획이 세워졌다면, 본격적인 진단 단계로 들어갑니다. 이 단계에서는 데이터의 구조와 값, 업무 규칙 등을 기준으로 진단을 위한 정보를 수집하고, 품질진단 기준에 알맞게 진단을 시작합니다.
- 데이터 형식의 일관성
- 중복 및 이상치 탐지
- 업무 규칙 위반 여부
- 기하 및 분포 속성 관찰
위 내용은 물론이고, ISO/IEC 25012/5259 데이터품질 평가 기준을 포함하여 다양한 품질 지표들을 점검할 수 있습니다. 또한 데이터클리닉에서는 레벨 1~3으로 나누어 품질을 진단하고 있습니다.
- Level 1 기초 진단: 데이터의 ‘기본 체력’을 점검하는 단계입니다. 데이터의 구조적 문제와 기본 규칙 위반 여부를 확인합니다.
- Level 2 일반형 렌즈 진단: 기초 진단에서 한 단계 더 들어가, 데이터 간 관계와 상관성을 다각도에서 분석하는 단계입니다.
- Level 3 데이터 특이적 렌즈 진단: 각 기업의 데이터 특성, 산업 맞춤형 정밀 진단을 진행합니다!
데이터클리닉에서는 그 결과로 이렇게 품질 진단 리포트를 제공합니다. 데이터의 건강 상태를 한눈에 확인할 수 있는 핵심 자료입니다! 데이터 진단 점수를 요약해 드리고, 데이터 경량화나 합성데이터 추가와 같은 개선 방향까지 제안해 드립니다.


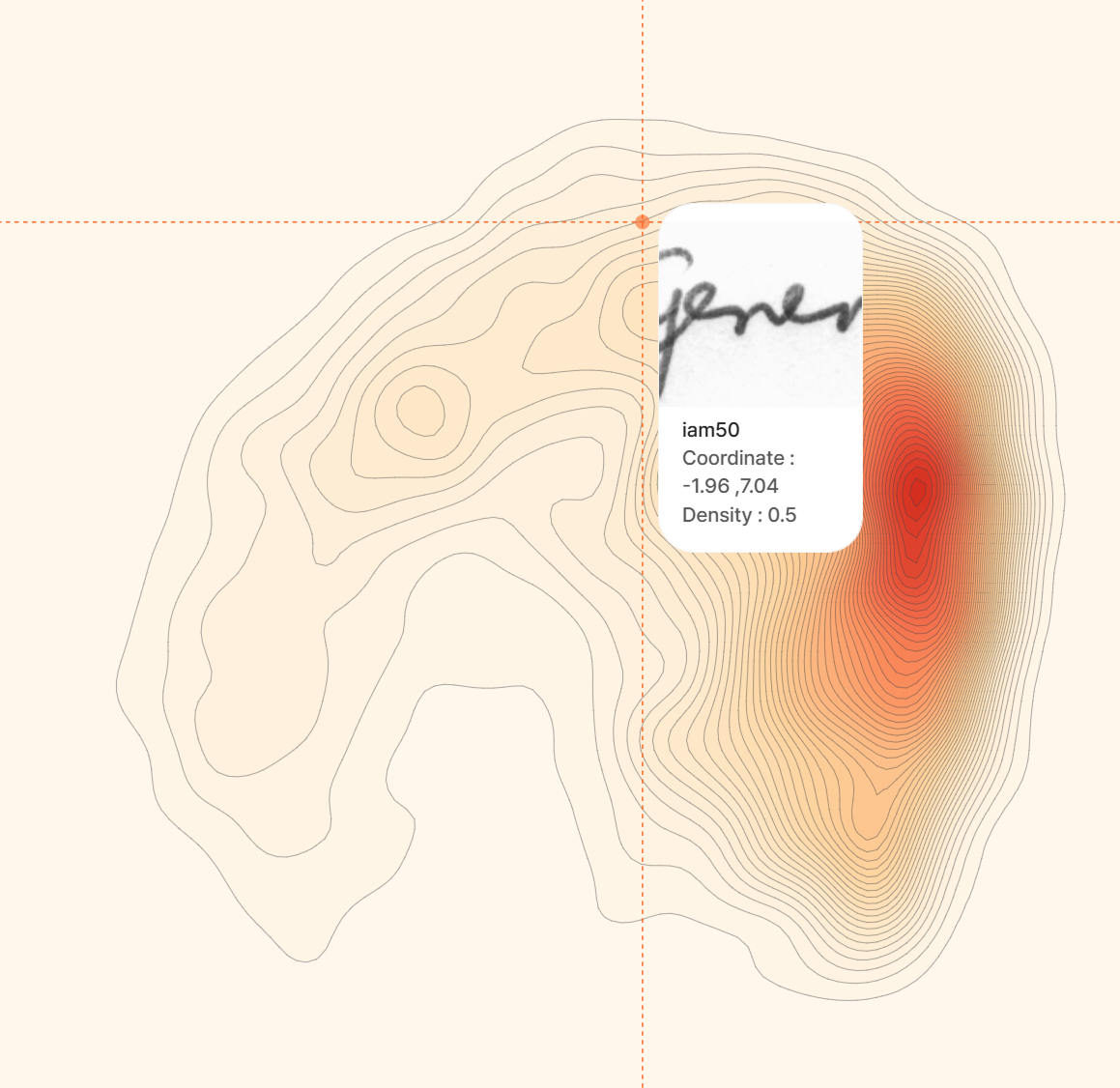
품질 진단 과정, 세부적으로 보고 싶다면?
3. 품질 개선
또한 품질진단의 최종 목표는 ‘품질 개선’입니다. 이때 품질 진단에서만 끝나는 게 아니라, 솔루션 내부에서 품질 개선까지 한 번에 이어진다면 어떨까요?
‘데이터 품질 관리 솔루션’, 데이터클리닉에서는 가능합니다. 데이터클리닉의 품질 개선은 데이터 다이어트, 데이터 벌크업, 데이터 레플리카로 구성돼요! 품질 진단 후, 세 가지 방법 중 정말 필요한 방법만 택해서 데이터를 개선합니다.
- 데이터 다이어트: 불필요하거나 중복된 데이터를 제거하여 데이터의 밀도와 효율성을 높이는 단계입니다.
- 데이터 벌크업: 학습에 반드시 필요하지만 아직 품질이 부족한 데이터를 풍부하게 만들어요! 데이터의 가치를 극대화하는 것이죠.
- 데이터 레플리카: 민감한 정보라도 고유의 정보를 보호하면서, 안전하게 합성 데이터를 생성할 수 있어요.
데이터 품질 진단, 개선을 했는데도 AI 성능이 오르지 이유
‘저희는 데이터 품질 진단부터 개선까지 했는데도 왜 AI 성능은 오르지 않는 걸까요? 뭐가 문제인지를 모르겠어요.’
꾸준히 품질 진단을 하고 있지만, 마음처럼 잘 풀리지 않는 상황입니다. 안타까운 상황에는 여러 가지 원인이 있지만, 그 중 3가지를 위주로 알아보겠습니다. 또한 각 해결 방법까지 말씀드리겠습니다.
1) ‘데이터 웨어하우스 속 데이터만’ 관리하기 때문입니다.
데이터 웨어하우스는 기업 내 데이터 분석의 중심입니다. 다만 그렇다고 해서 웨어하우스 속 데이터 위주로만 품질을 관리하는 것은 옳은 방향은 아닙니다.
실제 오류는 데이터 웨어하우스 바깥, 즉 모델링과 학습 과정에서 발생하기도 합니다. 예를 들어, 모델 학습 단계에서 잘못된 속성이 반영되거나, 중간 단계의 변환 로직에서 값이 누락되기도 하고요.
이 문제를 해결하려면 어떻게 해야 할까요? ‘넓고 깊게’ 분석해야 합니다.
- 넓게 분석하기: 데이터가 생성되고 수집·변환·저장·활용되는 모든 여정을 따라가며 관리해야 합니다.
- 깊게 분석하기: 표면적인 검수 수준만으로는 부족합니다. ‘데이터가 틀렸는지, 아닌지’만 확인하는 정도이기 때문인데요. 데이터의 형태, 분포, 상관관계, 이상 패턴 등을 수치적으로 분석하는 ‘데이터 프로파일링’ 기반 진단이 필요합니다.
우선 ‘프로파일링(Profiling)’의 뜻을 살펴볼까요? 사람의 특징을 분석해 패턴을 찾는 행위를 말합니다. 범행의 흔적과 행동 양식을 분석합니다. ‘이 사람은 어떤 성향이고, 어떤 상황에서 이런 행동을 할 가능성이 높다’는 패턴을 도출합니다.
‘데이터 프로파일링’도 이와 같습니다. 다만 대상이 ‘사람’에서 ‘데이터’로 바뀐 것뿐이죠.
- 범죄 프로파일링이 ‘사람의 행동 패턴’을 분석한다면, 데이터 프로파일링은 데이터의 분포와 이상 패턴을 분석합니다.
- 범죄 프로파일링이 ‘사건의 단서를 통해 범인을 추적’하듯, 데이터 프로파일링은 결측치, 중복, 이상값이라는 단서를 통해 데이터 오류의 근본 원인을 추적합니다.

2) 오류의 기준이 기업 구성원마다 다르기 때문입니다.
데이터 품질 진단 시 또 다른 어려움이 있습니다. ‘오류에 대한 기준’이 사람마다 다르다는 점인데요. 즉 여러분의 눈에는 분명히 ‘오류’로 보여도, 기업 내 다른 구성원이 보기에는 ‘이 정도면 괜찮은데?’라는 생각이 들 수도 있습니다.
예를 들어 한 데이터 엔지니어는 태깅이 불일치하면 품질관리 차원에서 오류로 볼 수도 있지만, 다른 쪽에서는 AI 서비스의 다양한 변수를 감안해서 유연하게 ‘허용 가능한 편차’ 정도로 여길 수 있는 것이죠.
이를 해결하기 위해서는 품질 진단과 품질 개선의 표준을 마련해야 합니다. 이를 공공기관과 민간기업으로 나누어서 설명해드리겠습니다.
공공기관
공공기관이라면 ‘공공데이터 품질관리 매뉴얼’을 참고해보세요!
- 매뉴얼을 기준으로 공공데이터를 관리한다면, ‘공공기관 기관평가’의 새로운 평가 항목에서 높은 점수를 얻을 수 있습니다.
- 민간이 공공데이터를 잘 활용할 수 있도록 데이터 품질을 관리하는 공공기관이 유리해지는 것이죠.

AI 솔루션을 개발하는 모든 기업
만약 내부에서 기준을 수립하는 게 어렵다면, 외부 전문가의 도움을 받아볼 수 있습니다. 외부 전문 기업을 통해 객관적으로 기준을 가지고 데이터를 진단/개선하는 것이죠!
페블러스의 AADS(자율형 데이터 과학자 기술, Agentic AI Data Scientist)을 접목한 ‘데이터클리닉 2.0’에서도 가능합니다! 데이터클리닉 2.0은 기존의 1.0과 비교해봤을 때 어떤 차이가 있을까요? 데이터클리닉 2.0에 대해 좀더 자세히 알아보겠습니다.
- 데이터클리닉 2.0은 기존 데이터클리닉 1.0의 품질 진단 기술에 ‘자율헝 데이터 과학자 기술’이 결합되었습니다.
- 데이터클리닉 2.0에서 챗GPT처럼 특정 데이터에 대한 진단, 개선을 요청해보세요. 데이터 과학에 특화된 LLM 기반 AI가 스스로 데이터를 자동으로 진단해주고 개선합니다.
- 여기에 데이터 품질 개선은 물론, 기업에 막대한 손실을 미칠 수 있는 규제까지 대응할 수 있어요. 기업 내부 규정부터 공공기관의 품질 관리 매뉴얼, 국제 표준 등의 객관적인 기준, 표준을 학습해요.
- AI로 인한 자율적인 데이터 품질 평가로 인해 데이터 품질을 365일 최고의 상태로 유지하는데요. 여러분의 데이터 품질 관리에 할애하는 업무 비용, 시간은 줄어들고, 업무의 효율은 높아집니다.
AADS의 작동 방식을 아래 링크 속 영상에서 확인해보세요.
AADS, 이렇게 작동해요!
데이터클리닉 웨비나를 통해 데이터 품질 진단 시점은 물론, 전문가의 비결을 확인해 보세요.
지금까지 데이터 품질 진단의 원리와 기준을 글 한 편에 담았지만, 사실 막상 이 모든 내용을 실제 기업 환경에 적용하는 일은 쉽지 않습니다.
이때 실제 사례를 확인해 본다면, 실질적인 도움이 될 것이라 생각합니다. 아래 데이터클리닉 웨비나 영상을 통해 이론을 넘어 실제 사례로 데이터 품질 진단 및 개선 과정을 확인해 보세요.
데이터클리닉 2.0을 개발한 페블러스의 이주행 대표님, 웨비나 영상 속 페블러스 이정원 부대표님은 ETRI 20년차 출신 데이터 과학자입니다.
더이상 데이터 품질 진단 시점을 놓치지 않고 싶다면 데이터클리닉에 문의해주세요. 데이터 품질 관리에 대해 어려움을 겪는 부분이 있다면 편히 말씀해주세요. 문의 버튼을 누르고, 고민을 작성하신 시간이 아깝지 않도록 깊이 있는 답변을 드리겠습니다!
데이터 품질 관리, 이제는 정답을 찾고 싶다면?
AI 모델의 데이터 품질을 매주 올리는 비결!